SQL COUNT() with GROUP by
COUNT() with GROUP by
The COUNT() function, when paired with the GROUP BY clause, is a powerful combination for summarizing and characterizing data under various groupings. This technique allows us to aggregate data based on specific columns, treating combinations of the same values as individual groups. It is especially useful in data analysis for identifying trends and patterns within grouped data.
Why Use COUNT() with GROUP BY?
Using COUNT() with GROUP BY is useful in many scenarios, such as:
- Calculate the number of occurrences for each unique value in a column.
- Analyzing the distribution of data across different segments.
- Summarizing large datasets by breaking them down into meaningful parts.
- Generate reports that show counts per category, such as sales per region or products per supplier.
Performance Tips:
- When working with large datasets, consider the following tips to optimize your queries:
- Indexing: Ensure the columns used in GROUP BY and ORDER BY are indexed.
- Avoid Grouping by High-Cardinality Columns: Grouping by columns with many unique values can be slow.
- Use EXPLAIN: Analyze your query execution plan using EXPLAIN to identify and resolve performance bottlenecks.
Common Pitfalls:
- Incorrect Grouping Columns: Ensure you group by the correct columns relevant to your analysis.
- Expecting Detailed Results: Remember that GROUP BY aggregates data, so individual row details are lost in the summary.
- Confusing WHERE and HAVING: Use WHERE to filter rows before grouping and HAVING to filter groups after aggregation.
Example:
We want to determine the number of agents operating in each distinct working area. This can be done with the following SQL query:
Sample table: agents
+------------+----------------------+--------------------+------------+-----------------+---------+ | AGENT_CODE | AGENT_NAME | WORKING_AREA | COMMISSION | PHONE_NO | COUNTRY | +------------+----------------------+--------------------+------------+-----------------+---------+ | A007 | Ramasundar | Bangalore | 0.15 | 077-25814763 | | | A003 | Alex | London | 0.13 | 075-12458969 | | | A008 | Alford | New York | 0.12 | 044-25874365 | | | A011 | Ravi Kumar | Bangalore | 0.15 | 077-45625874 | | | A010 | Santakumar | Chennai | 0.14 | 007-22388644 | | | A012 | Lucida | San Jose | 0.12 | 044-52981425 | | | A005 | Anderson | Brisban | 0.13 | 045-21447739 | | | A001 | Subbarao | Bangalore | 0.14 | 077-12346674 | | | A002 | Mukesh | Mumbai | 0.11 | 029-12358964 | | ....... | A009 | Benjamin | Hampshair | 0.11 | 008-22536178 | | +------------+----------------------+--------------------+------------+-----------------+---------+
SQL Code:
-- Selecting the 'working_area' column and counting the number of occurrences for each distinct value
SELECT working_area, COUNT(*)
-- From the 'agents' table
FROM agents
-- Grouping the results by the 'working_area' column
GROUP BY working_area;
Explanation:
- SELECT working_area, COUNT(*): This is the main part of the SQL query. It selects the 'working_area' column from the 'agents' table and counts the number of occurrences of each distinct value in the 'working_area' column using the COUNT(*) function. The result will include two columns: 'working_area' and the count of occurrences.
- FROM agents: This specifies the source of the data for the query, which is the 'agents' table. The FROM keyword is used to indicate the table from which the data will be selected. In this case, it selects data from the 'agents' table.
- GROUP BY working_area: This clause groups the result set by the 'working_area' column. The GROUP BY clause is used with aggregate functions like COUNT() to divide the rows returned from the SELECT statement into groups based on the values in one or more columns. In this case, it groups the rows based on the values in the 'working_area' column.
Relational Algebra Expression:
![]()
Relational Algebra Tree:
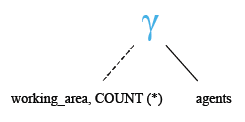
Output:
WORKING_AREA COUNT(*) ----------------------------------- ---------- San Jose 1 Torento 1 London 2 Hampshair 1 New York 1 Brisban 1 Bangalore 3 Chennai 1 Mumbai 1
Visual Presentation:
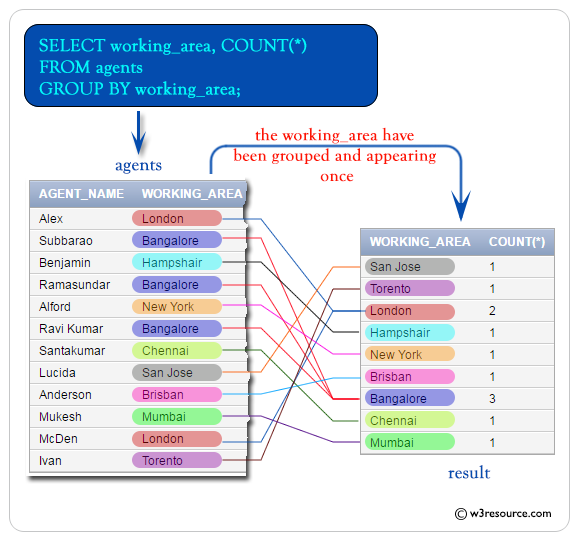
SQL COUNT( ) with group by and order by
In this page, we are going to discuss the usage of GROUP BY and ORDER BY along with the SQL COUNT() function.
The GROUP BY makes the result set in summary rows by the value of one or more columns. Each same value on the specific column will be treated as an individual group.
The utility of ORDER BY clause is, to arrange the value of a column ascending or descending, whatever it may the column type is numeric or character. The serial number of the column in the column list in the select statement can be used to indicate which columns have to be arranged in ascending or descending order.
The default order is ascending if not any keyword or mention ASCE is mentioned. DESC is mentioned to set it in descending order.
Example:
Sample table: agents
+------------+----------------------+--------------------+------------+-----------------+---------+ | AGENT_CODE | AGENT_NAME | WORKING_AREA | COMMISSION | PHONE_NO | COUNTRY | +------------+----------------------+--------------------+------------+-----------------+---------+ | A007 | Ramasundar | Bangalore | 0.15 | 077-25814763 | | | A003 | Alex | London | 0.13 | 075-12458969 | | | A008 | Alford | New York | 0.12 | 044-25874365 | | | A011 | Ravi Kumar | Bangalore | 0.15 | 077-45625874 | | | A010 | Santakumar | Chennai | 0.14 | 007-22388644 | | | A012 | Lucida | San Jose | 0.12 | 044-52981425 | | | A005 | Anderson | Brisban | 0.13 | 045-21447739 | | | A001 | Subbarao | Bangalore | 0.14 | 077-12346674 | | | A002 | Mukesh | Mumbai | 0.11 | 029-12358964 | | ......... | A009 | Benjamin | Hampshair | 0.11 | 008-22536178 | | +------------+----------------------+--------------------+------------+-----------------+---------+
To get data of 'working_area' and number of agents for this 'working_area' from the 'agents' table with following conditions -
1. 'working_area' should come uniquely,
2. counting for each group should come in ascending order,
the following SQL statement can be used:
SQL Code:
-- Selecting the 'working_area' column and counting the number of occurrences for each distinct value
SELECT working_area, COUNT(*)
-- From the 'agents' table
FROM agents
-- Grouping the results by the 'working_area' column
GROUP BY working_area
-- Sorting the results by the second column (COUNT(*)) in ascending order
ORDER BY 2;
Explanation:
- SELECT working_area, COUNT(*): This is the main part of the SQL query. It selects the 'working_area' column from the 'agents' table and counts the number of occurrences of each distinct value in the 'working_area' column using the COUNT(*) function. The result will include two columns: 'working_area' and the count of occurrences.
- FROM agents: This specifies the source of the data for the query, which is the 'agents' table. The FROM keyword is used to indicate the table from which the data will be selected. In this case, it selects data from the 'agents' table.
- GROUP BY working_area: This clause groups the result set by the 'working_area' column. The GROUP BY clause is used with aggregate functions like COUNT() to divide the rows returned from the SELECT statement into groups based on the values in one or more columns. In this case, it groups the rows based on the values in the 'working_area' column.
- ORDER BY 2: This clause orders the result set by the second column. In SQL, column positions can be referred to by their ordinal position in the SELECT list. Here, ORDER BY 2 orders the result set by the count of occurrences, which is the second column in the SELECT list (after 'working_area'). This sorts the result set in ascending order based on the count of occurrences.
Relational Algebra Expression:
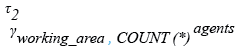
Relational Algebra Tree:
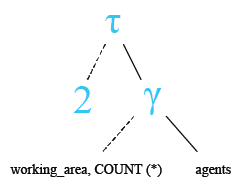
Output:
WORKING_AREA COUNT(*) ----------------------------------- ---------- San Jose 1 Torento 1 New York 1 Chennai 1 Hampshair 1 Mumbai 1 Brisban 1 London 2 Bangalore 3
SQL COUNT( ) group by and order by in descending
To get data of 'working_area' and number of agents for this 'working_area' from the 'agents' table with the following conditions -
1. ' working_area' should come uniquely,
2. counting for each group should come in descending order,
the following SQL statement can be used :
Sample table: agents
+------------+----------------------+--------------------+------------+-----------------+---------+ | AGENT_CODE | AGENT_NAME | WORKING_AREA | COMMISSION | PHONE_NO | COUNTRY | +------------+----------------------+--------------------+------------+-----------------+---------+ | A007 | Ramasundar | Bangalore | 0.15 | 077-25814763 | | | A003 | Alex | London | 0.13 | 075-12458969 | | | A008 | Alford | New York | 0.12 | 044-25874365 | | | A011 | Ravi Kumar | Bangalore | 0.15 | 077-45625874 | | | A010 | Santakumar | Chennai | 0.14 | 007-22388644 | | | A012 | Lucida | San Jose | 0.12 | 044-52981425 | | | A005 | Anderson | Brisban | 0.13 | 045-21447739 | | | A001 | Subbarao | Bangalore | 0.14 | 077-12346674 | | | A002 | Mukesh | Mumbai | 0.11 | 029-12358964 | | ....... | A009 | Benjamin | Hampshair | 0.11 | 008-22536178 | | +------------+----------------------+--------------------+------------+-----------------+---------+
SQL Code:
-- Selecting the 'working_area' column and counting the number of occurrences for each distinct value
SELECT working_area, COUNT(*)
-- From the 'agents' table
FROM agents
-- Grouping the results by the 'working_area' column
GROUP BY working_area
-- Sorting the results by the second column (COUNT(*)) in descending order
ORDER BY 2 DESC;
Explanation:
- SELECT working_area, COUNT(*): This is the main part of the SQL query. It selects the 'working_area' column from the 'agents' table and counts the number of occurrences of each distinct value in the 'working_area' column using the COUNT(*) function. The result will include two columns: 'working_area' and the count of occurrences.
- FROM agents: This specifies the source of the data for the query, which is the 'agents' table. The FROM keyword is used to indicate the table from which the data will be selected. In this case, it selects data from the 'agents' table.
- GROUP BY working_area: This clause groups the result set by the 'working_area' column. The GROUP BY clause is used with aggregate functions like COUNT() to divide the rows returned from the SELECT statement into groups based on the values in one or more columns. In this case, it groups the rows based on the values in the 'working_area' column.
- ORDER BY 2 DESC: This clause orders the result set by the second column in descending order. In SQL, column positions can be referred to by their ordinal position in the SELECT list. Here, ORDER BY 2 DESC orders the result set by the count of occurrences, which is the second column in the SELECT list (after 'working_area'). The DESC keyword specifies that the ordering should be in descending order.
Relational Algebra Expression:
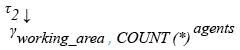
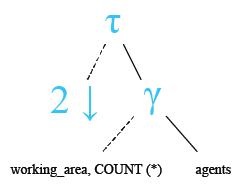
Relational Algebra Tree:
Output:
WORKING_AREA COUNT(*) ----------------------------------- ---------- Bangalore 3 London 2 Hampshair 1 Mumbai 1 Brisban 1 Chennai 1 Torento 1 San Jose 1 New York 1
GROUP BY with Multiple Columns:
To count the number of agents for each combination of working_area and agent_name:
the following SQL statement can be used :
Sample table : agents_sqt
+------------+----------------------+--------------------+------------+-----------------+---------+ | AGENT_CODE | AGENT_NAME | WORKING_AREA | COMMISSION | PHONE_NO | COUNTRY | +------------+----------------------+--------------------+------------+-----------------+---------+ | A007 | Ramasundar | Bangalore | 0.15 | 077-25814763 | | | A003 | Alex | London | 0.13 | 075-12458969 | | | A008 | Alford | New York | 0.12 | 044-25874365 | | | A011 | Ravi Kumar | Bangalore | 0.15 | 077-45625874 | | | A010 | Santakumar | Chennai | 0.14 | 007-22388644 | | | A012 | Lucida | San Jose | 0.12 | 044-52981425 | | | A005 | Anderson | Brisban | 0.13 | 045-21447739 | | | A001 | Subbarao | Bangalore | 0.14 | 077-12346674 | | | A002 | Mukesh | Mumbai | 0.11 | 029-12358964 | | ....... | A009 | Benjamin | Hampshair | 0.11 | 008-22536178 | | +------------+----------------------+--------------------+------------+-----------------+---------+
SQL Code:
-- Selecting the 'working_area' column to group by working area
-- Selecting the 'agent_name' column to group by agent name
-- Using the COUNT(*) function to count the number of rows for each group
SELECT working_area, agent_name, COUNT(*)
-- Specifying the 'agents_sqt' table to retrieve data from
FROM agents_sqt
-- Grouping the results by both 'working_area' and 'agent_name' columns
GROUP BY working_area, agent_name;
Explanation:
- This SQL query retrieves the working_area and agent_name columns from the agents_sqt table and counts the number of occurrences for each unique combination of working_area and agent_name.
- By using the GROUP BY clause, the query groups the rows based on the working_area and agent_name columns, allowing the COUNT(*) function to calculate the number of rows in eachgroup.
Output:
working_area|agent_name|count| ------------+----------+-----+ Chennai |Santakumar| 1| New York |Alford | 1| Bangalore |Ravi Kumar| 1| London |McDen | 1| Mumbai |Mukesh | 1| Bangalore |Ramasundar| 1| San Jose |Lucida | 1| Brisban |Anderson | 1| Bangalore |Subbarao | 1| London |Alex | 1| Torento |Ivan | 1| Hampshair |Benjamin | 1|
Filtering Groups with HAVING:
To list only the working areas with more than one agent:
the following SQL statement can be used :
Sample table : agents_sqt
+------------+----------------------+--------------------+------------+-----------------+---------+ | AGENT_CODE | AGENT_NAME | WORKING_AREA | COMMISSION | PHONE_NO | COUNTRY | +------------+----------------------+--------------------+------------+-----------------+---------+ | A007 | Ramasundar | Bangalore | 0.15 | 077-25814763 | | | A003 | Alex | London | 0.13 | 075-12458969 | | | A008 | Alford | New York | 0.12 | 044-25874365 | | | A011 | Ravi Kumar | Bangalore | 0.15 | 077-45625874 | | | A010 | Santakumar | Chennai | 0.14 | 007-22388644 | | | A012 | Lucida | San Jose | 0.12 | 044-52981425 | | | A005 | Anderson | Brisban | 0.13 | 045-21447739 | | | A001 | Subbarao | Bangalore | 0.14 | 077-12346674 | | | A002 | Mukesh | Mumbai | 0.11 | 029-12358964 | | ....... | A009 | Benjamin | Hampshair | 0.11 | 008-22536178 | | +------------+----------------------+--------------------+------------+-----------------+---------+
SQL Code:
-- Selecting the 'working_area' column to group by working area
-- Using the COUNT(*) function to count the number of rows for each group
SELECT working_area, COUNT(*)
-- Specifying the 'agents_sqt' table to retrieve data from
FROM agents_sqt
-- Grouping the results by the 'working_area' column
GROUP BY working_area
-- Filtering the groups to include only those having more than 1 row
HAVING COUNT(*) > 1;
Explanation:
- This SQL query selects the working_area column from the agents_sqt table and counts the number of occurrences for each unique working_area.
- The GROUP BY clause groups the rows by the working_area column.
- The HAVING clause filters the results to include only those groups where the count of rows is greater than 1, effectively displaying only the working areas with multiple agents.
Output:
working_area|count| ------------+-----+ London | 2| Bangalore | 3|
Combining GROUP BY with Other Aggregate Functions:
In addition to COUNT(), you can use other aggregate functions like SUM(), AVG(), MIN(), and MAX() with GROUP BY to derive more insights.
For example, if you have a sales table, you might want to know the total sales for each product:To list only the working areas with more than one agent:
the following SQL statement can be used :
Sample table : sales_sqt
sale_id|sale_amount|product_id|
-------+-----------+----------+
1| 150000.00| 101|
2| 25000.50| 103|
3| 75.75| 103|
4| 1200.00| 104|
5| 43000.30| 101|
6| 21500.40| 102|
7| 870.10| 104|
8| 990.50| 104|
9| 33000.33| 103|
10| 580.80| 104|
SQL Code:
-- Selecting the 'product_id' column to identify each product
-- Using the SUM(sale_amount) function to calculate the total sales amount for each product
SELECT product_id, SUM(sale_amount)
-- Specifying the 'sales_sqt' table to retrieve data from
FROM sales_sqt
-- Grouping the results by the 'product_id' column
GROUP BY product_id;
Explanation:
- This SQL query retrieves the product_id and the total sale_amount for each product from the sales_sqt table.
- The GROUP BY clause groups the sales data by product_id, allowing the SUM(sale_amount) function to calculate the total sales amount for each product.
- This provides a summary of the total sales for each distinct product.
Output:
product_id|sum |
----------+---------+
101|193000.30|
103| 58076.58|
104| 3641.40|
102| 21500.40|
Frequently Asked Questions (FAQ) - SQL COUNT() with GROUP BY:
1. What is the purpose of using SQL COUNT() with the GROUP BY clause?
The SQL COUNT() function, combined with the GROUP BY clause, is used to aggregate and summarize data based on specific columns. This allows for counting occurrences within distinct groups formed by the column values specified in the GROUP BY clause.
2. In what scenarios is COUNT() with GROUP BY particularly useful?
COUNT() with GROUP BY is useful in scenarios where you need to:
- Count the occurrences of each unique value in a column.
- Analyze data distribution across different segments.
- Summarize large datasets into meaningful parts.
- Generate reports that show counts per category, like sales per region or products per supplier.
3. How can we optimize the performance of queries using COUNT() with GROUP BY on large datasets?
To optimize performance, we can:
- Ensure that columns used in GROUP BY and ORDER BY are indexed.
- Avoid grouping by high-cardinality columns (columns with many unique values).
4. What are some common mistakes to avoid when using COUNT() with GROUP BY?
Common pitfalls include:
- Incorrect grouping columns: Make sure to group by the correct columns that are relevant to your analysis.
- Expecting detailed results: GROUP BY aggregates data, so detailed row information is lost in the summary.
- Confusing WHERE and HAVING clauses: Use WHERE to filter rows before grouping and HAVING to filter groups after aggregation.
5. What is the difference between the WHERE and HAVING clauses when using GROUP BY?
- WHERE is used to filter rows before the grouping occurs.
- HAVING is used to filter groups after the aggregation has been applied.
6. Can we use GROUP BY with multiple columns?
Yes, GROUP BY can be used with multiple columns to group data by combinations of values in those columns. This allows for more detailed aggregations and insights into how data is distributed across multiple dimensions.
7. How does the ORDER BY clause work with GROUP BY and COUNT()?
The ORDER BY clause sorts the result set based on one or more columns. When used with GROUP BY and COUNT(), it can sort the aggregated results either by the grouped columns or by the aggregate function's result, such as the count of occurrences.
8. What other aggregate functions can be used with GROUP BY besides COUNT()?
In addition to COUNT(), other aggregate functions like SUM(), AVG(), MIN(), and MAX() can be used with GROUP BY. These functions allow you to perform various types of aggregations on grouped data, providing more comprehensive summaries and insights.
9. How can we filter groups to only include those with specific conditions using GROUP BY?
We can use the HAVING clause to filter groups based on conditions applied to aggregate functions. For example, we can filter groups to include only those with a count greater than a certain number.
10. Why is it important to ensure columns used in GROUP BY are indexed?
Indexing columns used in GROUP BY improves query performance by allowing the database to quickly locate and aggregate rows with matching values. This is particularly beneficial when dealing with large datasets.
PREV : COUNT with Distinct
NEXT : COUNT Having and Group by