Using Buffers in Node.js
Introduction
Pure JavaScript does not handle straight binary data very well, though JavaScript is Unicode friendly. When dealing with TCP streams and reading and writing to the filesystem, it is necessary to deal with purely binary streams of data.
Node has several strategies for manipulating, creating, and consuming octet ( One octet can be used to represent decimal values ranging from 0 to 255.) streams. Raw data is stored in instances of the Buffer class ( which is designed to handle raw binary data) in the node.
Note : An octet is a unit of digital information in computing and telecommunications that consist of eight bits. The term is often used when the term byte might be ambiguous, as historically there was no standard definition for the size of the byte.
A buffer is a region of a physical memory storage used to temporarily store data while it is being moved from one place to another. In node, each buffer corresponds to some raw memory allocated outside V8. A buffer acts like an array of integers, but cannot be resized. The Buffer class is global. It deals with binary data directly and can be constructed in a variety of ways.
Encoding list, used with node
Converting between Buffers and JavaScript string objects requires an explicit encoding method. The following table shows the different string encodings.
| Encoding | Description |
|---|---|
| 'ascii' | for 7 bit ASCII data only. This encoding method is way fast, but is limited to the ascii character set. To convert a null character into 0x00, you should use 'utf8'. |
| 'utf8' | Multibyte encoded Unicode characters. It has become the dominant character encoding for the world wide web. |
| 'utf16le' | 2 or 4 bytes, little-endian encoded Unicode characters, surrogate pairs (U+10000 to U+10FFFF) are supported. |
| 'ucs2' | Alias of 'utf16le'. |
| 'base64' | Base64 string encoding. |
| 'binary' | Method of encoding raw binary data into strings by using only the first 8 bits of each character. This encoding method is deprecated. |
| 'hex' | This method is used to encode each byte as two hexadecimal characters. |
Creating Buffers in Node
There are several ways to create new buffers.
new Buffer(n)
new Buffer(n) is used to create a new buffer of 'n' octets, where 'n' is a number
Arguments :
| Name | Description | Type |
|---|---|---|
| n | Size of the buffer. | number |
In the following example 'buffer' contains 10 octets.
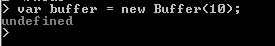
new Buffer(arr):
new Buffer(arr) is used to create a new buffer, using an array of octets.
Arguments :
| Name | Description | Type |
|---|---|---|
| arr | A given array. | array |
In the following example roll_no contains the contents of an array. See the output.
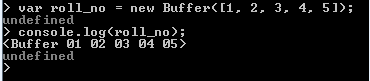
new Buffer(str, [encoding]):
new Buffer(str, [encoding]) is used to create a new buffer, contains a given string.
Arguments :
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| str | A given string | Required | string |
| encoding | Encoding to use. 'utf8' is the default encoding. See the encoding list. |
Optional | string |
See the following example :

In the above log output, the buffer object contains 18 bytes of data represented in hexadecimal.
Test valid encoding type - Buffer.isEncoding(encoding):
The isEncoding() method is used to test whether an encoding string is a valid encoding type or not.
Arguments :
| Name | Description | Type |
|---|---|---|
| encoding | Encoding type. | string |
Return value : Returns true for valid encoding argument, or false otherwise.
See the following examples :
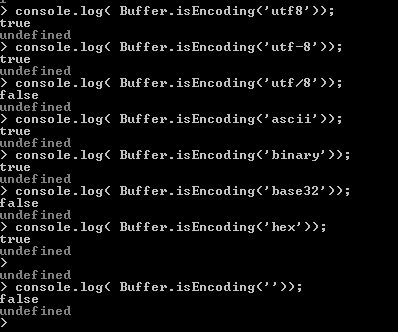
Writing to Buffers
buf.write(string, [offset], [length], [encoding]):
The buf.write(str, [offset], [length], [encoding]) method is used to write a string to the buffer.
Arguments:
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| str | A given string. | Required | string |
| offset | An offset, or the index of the buffer to start writing at. Default value is 0. | Optional | number |
| length | Number of bytes to write. Defaults to buffer.length - offset. | Optional | number |
| encoding | Encoding to use. 'utf8' is the default encoding. See the encoding list. | Optional | string |
Return Value : Number of octets written. If there is not enough space in the buffer to fit the entire string, it will write a part of the string.
Examples :
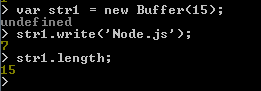
Let create a buffer of size 15 octtets.

Now write a string to it :

In the above example, the first argument to buffer.write is the string ("Node.js") to write to the buffer, and the second argument is the string encoding ("utf8"). In this case, second argument is not mandatory as "utf8" is the default encoding.
str1.write has returned 7, i.e. we have written seven bytes of the buffer. The length of the string "Node.js" is also seven.
Here is an another example where we have added all three arguments, the second argument indicates an offset.

Reading from Buffers
buf.toString([encoding], [start], [end])
The buf.toString([encoding], [start], [end]) method decodes and returns a string from buffer data. Here in 'buf' data has already written through buffers writing method.
Arguments :
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| encoding | Encoding to use. 'utf8' is the default encoding. See the encoding list. | Optional | string |
| start | Beginning at the start, defaults to 0. | Optional | number |
| end | Ending at the end. Defaults to buffer.length. | Optional | number |
Return Value : A string.
In the following example we have created a buffer of size 15 octets, then write a string 'Node.js'. The first toString() method reads the entire buffer and shows some null characters ('\u0000'), since the buffer does not contain all text characters. The second one read the buffer characters from 0 to 7th position and returns 'Node.js'.
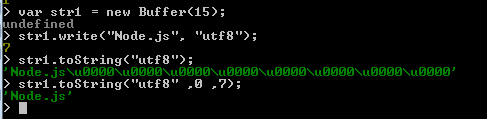
JSON representation : buf.toJSON()
The buf.toJSON() method is used to get the JSON-representation of the Buffer instance, which is identical to the output for JSON Arrays. Here is an example :
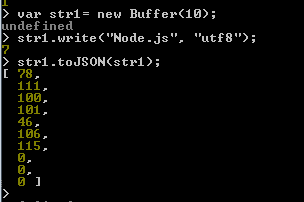
The buffer size of str1 was 10 and length of the specified string is 7, therefore, the last three values within the array shows 0.
Setting individual octet : buf[index]
The buf[index] is used to get and set the octet at index. The values refer to individual bytes, the legal range is between 0x00 and 0xFF hex or 0 and 255. In the following example, we have inserted three '*' characters at the end of the 'Node.js' string within the buffer.
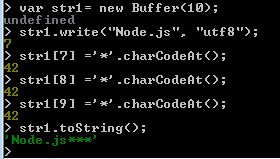
Note : See the details of charCodeAt() Method at here.
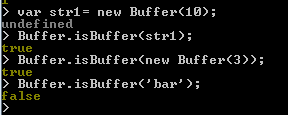
Tests if an Object is a Buffer - Buffer.isBuffer(obj):
Buffer.isBuffer(obj) method is used to check whether an object in Node.js Buffer or not.
Return Value : Return true if the object is a Buffer or false otherwise.
Value Type : Boolean.
See the following examples :
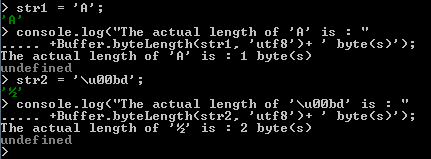
Actual byte length of a string : Buffer.byteLength(str, [encoding])
Buffer.byteLength(string, [encoding]) method is used to get the actual byte length of a string with a given encoding.
Arguments :
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| str | A given string. | Required | string |
| encoding | Encoding to use. 'utf8' is the default encoding. See the encoding list. | Optional | string |
Return Value : Actual byte length of a string.
Value Type : number.
In the following examples, actual string length of 'A' is 1 byte, whereas length of '\u00bd' is 2 bytes.
Concat two for more buffers : Buffer.concat(list, [totalLength]
The Buffer.concat(list, [totalLength]) method is used to concatenate two or more buffers/strings.
Arguments :
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| list | List of Buffer objects to concat | Required | array |
| totalLength | Total length of the buffers when concatenated. | Optional | number |
Return Value : A buffer
- If the list has no items, or if the totalLength is 0, then it returns a zero-length buffer.
- If the list has exactly one item, then the first item of the list is returned.
- If the list has more than one item, then a new Buffer is created.
- If totalLength is not provided, it is read from the buffers in the list. However, this adds an additional loop to the function, so it is faster to provide the length explicitly.
See the following examples :
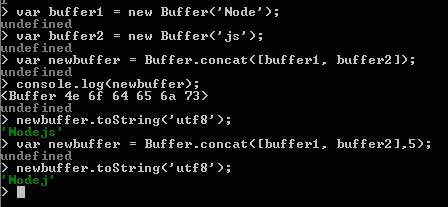
The length of buffer1 is 4 and buffer2 are 2. In the last example we have mentioned the total length of the buffers (5) therefore it shows 'Nodej' not 'Nodejs'.
The length of the buffer in bytes - buf.length
The buf.length method is used to get the size of the buffer and represents how much memory is allocated. It is not the same as the size of the buffer's contents, since a buffer may one-third filled. For example :
Buffer copy : buf.copy(targetBuffer, [targetStart], [sourceStart], [sourceEnd])
The buf.copy(targetBuffer, [targetStart], [sourceStart], [sourceEnd]) method is used to copy the contents of one buffer onto another.
Arguments :
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| targetBuffer | Buffer to copy into. | Required | Buffer object |
| targetStart | Starting position of the target Buffer. Default to 0. | Optional | number |
| sourceStart | Starting position of the source Buffer. Default to 0. | Optional | number |
| sourceEnd | End position of the source Buffer. Default to buffer.length. | Optional | number |
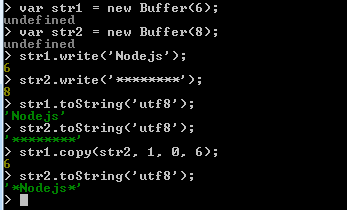
In the following example, 'str1' buffer (lenght, 6) has copied, to the "str2" buffer (length, 8) from the second byte.
Slice a Buffer : buf.slice([start], [end])
The buf.slice([start], [end]) method is used to extract a subsection of the buffer which references the same memory as the old.
Arguments :
| Name | Description | Required / Optional | Type |
|---|---|---|---|
| start | Starting position into the buffer. Defaults to 0. | Optional | number |
| end | End position into the buffer. Defaults to buffer.length. | Optional | number |
Note : Negative indexes start from the end of the buffer.
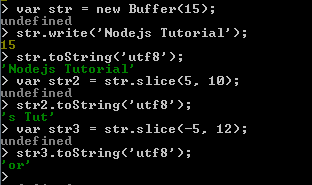
Here are some examples :
Previous:
Console Logging
Next:
OS Module