Python Web Scraping: Extract and display all the image links from en.wikipedia.org/wiki/Peter_Jeffrey_(RAAF_officer)
Write a Python program to extract and display all the image links from en.wikipedia.org/wiki/Peter_Jeffrey_(RAAF_officer).
Sample Solution:
Python Code:
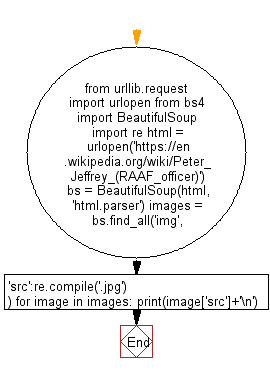
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('https://en.wikipedia.org/wiki/Peter_Jeffrey_(RAAF_officer)')
bs = BeautifulSoup(html, 'html.parser')
images = bs.find_all('img', {'src':re.compile('.jpg')})
for image in images:
print(image['src']+'\n')
Sample Output:
//upload.wikimedia.org/wikipedia/commons/thumb/a/af/NlaJeffrey1942-43.jpg/220px-NlaJeffrey1942-43.jpg //upload.wikimedia.org/wikipedia/commons/thumb/c/c5/008315JeffreyTurnbull1941.jpg/260px-008315JeffreyTurnbull1941.jpg //upload.wikimedia.org/wikipedia/commons/e/ea/021807CameronJeffrey1941.jpg //upload.wikimedia.org/wikipedia/commons/thumb/9/92/AC0072JeffreyTruscottKittyhawks1942.jpg/280px-AC0072JeffreyTruscottKittyhawks1942.jpg //upload.wikimedia.org/wikipedia/commons/thumb/2/26/VIC1689Jeffrey1945.jpg/280px-VIC1689Jeffrey1945.jpg
Flowchart:
Python Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
Previous: Write a Python program to extract and display all the header tags from en.wikipedia.org/wiki/Main_Page
Next: Write a Python program to get 90 days of visits broken down by browser for all sites on data.gov.
What is the difficulty level of this exercise?