Python Web Scraping: Display the contains of different attributes of a specified resource
Write a Python program to display the contains of different attributes like status_code, headers, url, history, encoding, reason, cookies, elapsed, request and content of a specified resource.
Sample Solution:
Python Code:
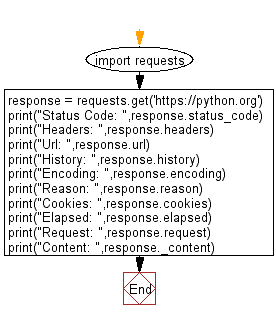
import requests
response = requests.get('https://python.org')
print("Status Code: ",response.status_code)
print("Headers: ",response.headers)
print("Url: ",response.url)
print("History: ",response.history)
print("Encoding: ",response.encoding)
print("Reason: ",response.reason)
print("Cookies: ",response.cookies)
print("Elapsed: ",response.elapsed)
print("Request: ",response.request)
print("Content: ",response._content)
Sample Output:
Status Code: 200
Headers: {'Server': 'nginx', 'Content-Type': 'text/html; charset=utf-8', 'X-Frame-Options': 'DENY', 'Via': '1.1 vegur, 1.1 varnish, 1.1 varnish', 'Content-Length': '49144', 'Accept-Ranges': 'bytes', 'Date': 'Fri, 07 Jun 2019 09:13:20 GMT', 'Age': '1021', 'Connection': 'keep-alive', 'X-Served-By': 'cache-iad2145-IAD, cache-bom18222-BOM', 'X-Cache': 'HIT, HIT', 'X-Cache-Hits': '2, 26', 'X-Timer': 'S1559898800.373555,VS0,VE0', 'Vary': 'Cookie', 'Strict-Transport-Security': 'max-age=63072000; includeSubDomains'}
Url: https://www.python.org/
History: [<Response [301]>]
Encoding: utf-8
Reason: OK
Cookies: <RequestsCookieJar[]>
Elapsed: 0:00:00.280475
Request: <PreparedRequest [GET]>
Content: b'<!doctype html>\n<!--[if lt IE 7]> <html class="no-js ie6 lt-ie7 lt-ie8 lt-ie9"> <![endif]-->\n<!--[if IE 7]> <html class="no-js ie7 lt-ie8 lt-ie9"> <![endif]-->\n<!--[if IE 8]> <html class="no-js ie8 lt-ie9"> <![endif]-->\n<!--[if gt IE 8]><!--><html class="no-js" lang="en" dir="ltr"> <!--<![endif]-->\n\n<head>\n
........
</div>\n\n </div><!-- end .container -->\n </div><!-- end .site-base -->\n\n </footer>\n\n </div><!-- end #touchnav-wrapper -->\n\n \n <script src="//ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js"></script>\n <script>window.jQuery || document.write(\'<script src="/static/js/libs/jquery-1.8.2.min.js"><\\/script>\')</script>\n\n <script src="/static/js/libs/masonry.pkgd.min.js"></script>\n <script src="/static/js/libs/html-includes.js"></script>\n\n <script type="text/javascript" src="/static/js/main-min.fbfe252506ae.js" charset="utf-8"></script>\n \n\n <!--[if lte IE 7]>\n <script type="text/javascript" src="/static/js/plugins/IE8-min.16868e6a5d2f.js" charset="utf-8"></script>\n \n \n <![endif]-->\n\n <!--[if lte IE 8]>\n <script type="text/javascript" src="/static/js/plugins/getComputedStyle-min.c3860be1d290.js" charset="utf-8"></script>\n \n \n <![endif]-->\n\n \n\n \n \n\n</body>\n</html>\n'
Flowchart:
Python Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
Previous: Write a Python program to get the number of magnitude 4.5+ earthquakes detected worldwide by the USGS.
Next: Write a Python program to verifiy SSL certificates for HTTPS requests using requests module.
What is the difficulty level of this exercise?