Java thread Programming - Simultaneous Website Crawling
6. Build a concurrent web crawler with threads
Write a Java program to implement a concurrent web crawler that crawls multiple websites simultaneously using threads.
Note:
jsoup: Java HTML Parser
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CSS selectors.
Download and install jsoup from here.
Sample Solution:
Java Code:
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Web_Crawler {
private static final int MAX_DEPTH = 2; // Maximum depth for crawling
private static final int MAX_THREADS = 4; // Maximum number of threads
private final Set < String > visitedUrls = new HashSet < > ();
public void crawl(String url, int depth) {
if (depth > MAX_DEPTH || visitedUrls.contains(url)) {
return;
}
visitedUrls.add(url);
System.out.println("Crawling: " + url);
try {
Document document = Jsoup.connect(url).get();
processPage(document);
Elements links = document.select("a[href]");
for (Element link: links) {
String nextUrl = link.absUrl("href");
crawl(nextUrl, depth + 1);
}
} catch (IOException e) {
e.printStackTrace();
}
}
public void processPage(Document document) {
// Process the web page content as needed
System.out.println("Processing: " + document.title());
}
public void startCrawling(String[] seedUrls) {
ExecutorService executor = Executors.newFixedThreadPool(MAX_THREADS);
for (String url: seedUrls) {
executor.execute(() -> crawl(url, 0));
}
executor.shutdown();
try {
executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Crawling completed.");
}
public static void main(String[] args) {
// Add URLs here
String[] seedUrls = {
"https://example.com",
"https://www.wikipedia.org"
};
Web_Crawler webCrawler = new Web_Crawler();
webCrawler.startCrawling(seedUrls);
}
}
Sample Output:
Crawling: https://www.wikipedia.org Crawling: https://example.com Processing: Wikipedia Crawling: https://en.wikipedia.org/ Processing: Example Domain Crawling: https://www.iana.org/domains/example Processing: Wikipedia, the free encyclopedia Crawling: https://en.wikipedia.org/wiki/Main_Page#bodyContent Processing: Wikipedia, the free encyclopedia Crawling: https://en.wikipedia.org/wiki/Main_Page Processing: Wikipedia, the free encyclopedia Crawling: https://en.wikipedia.org/wiki/Wikipedia:Contents Processing: Wikipedia:Contents - Wikipedia Crawling: https://en.wikipedia.org/wiki/Portal:Current_events Processing: Portal:Current events - Wikipedia Crawling: https://en.wikipedia.org/wiki/Special:Random Processing: IANA-managed Reserved Domains Crawling: http://www.iana.org/ Processing: Papilio birchallii - Wikipedia Crawling: https://en.wikipedia.org/wiki/Wikipedia:About Processing: Wikipedia:About - Wikipedia Crawling: https://en.wikipedia.org/wiki/Wikipedia:Contact_us Processing: Internet Assigned Numbers Authority Crawling: http://www.iana.org/domains Processing: Wikipedia:Contact us - Wikipedia Crawling: https://donate.wikimedia.org/wiki/Special:FundraiserRedirector?utm_source=donate&utm_medium=sidebar&utm_campaign=C13_en.wikipedia.org&uselang=en Processing: Domain Name Services Crawling: http://www.iana.org/protocols Processing: Make your donation now - Wikimedia Foundation Crawling: https://en.wikipedia.org/wiki/Help:Contents Processing: Help:Contents - Wikipedia Crawling: https://en.wikipedia.org/wiki/Help:Introduction Processing: Help:Introduction - Wikipedia
Pictorial Presentation:
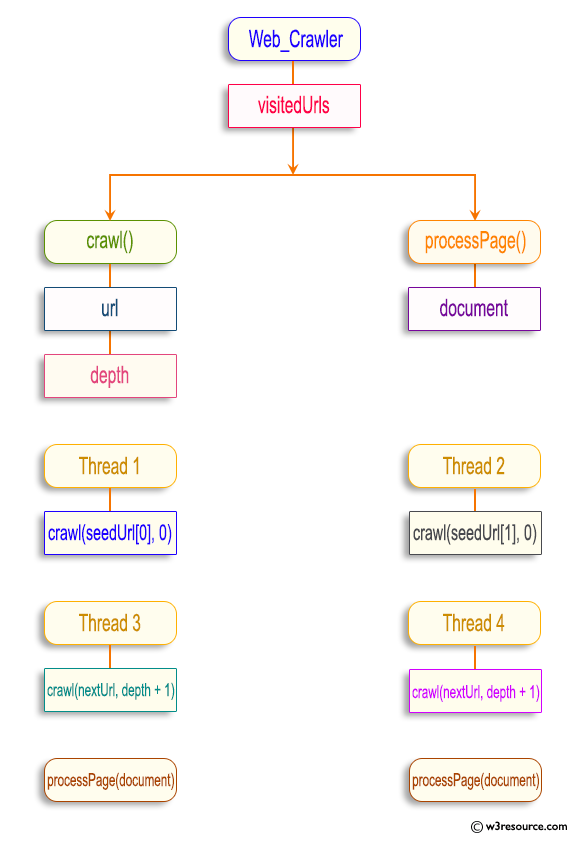
Explanation:
In the above exercise,
- The Web_Crawler class crawls web pages. It has two constants:
- MAX_DEPTH: Represents the maximum depth to which the crawler explores links on a web page.
- MAX_THREADS: Represents the maximum number of threads to use for crawling.
- The class maintains a Set<String> called visitedUrls to keep track of the URLs visited during crawling.
- The crawl(String url, int depth) method crawls a given URL up to a specified depth. If the current depth exceeds MAX_DEPTH or if the URL has already been visited, the method returns. Otherwise, it adds the URL to the visitedUrls set. It prints a message indicating that the URL is being crawled, and retrieves the web page using the Jsoup library.
- The processPage(Document document) method represents web page processing. In this example, it simply prints the document title. You can customize this method to perform specific operations on web page content.
- The startCrawling(String[] seedUrls) method initiates the crawling process. It creates a fixed-size thread pool using ExecutorService and Executors.newFixedThreadPool() with a maximum number of threads specified by MAX_THREADS. It then submits crawl tasks for each seed URL in the seedUrls array to the thread pool for concurrent execution.
- After submitting all the tasks, the method shuts down the executor, waits for all the tasks to complete using executor.awaitTermination(), and prints a completion message.
Flowchart:
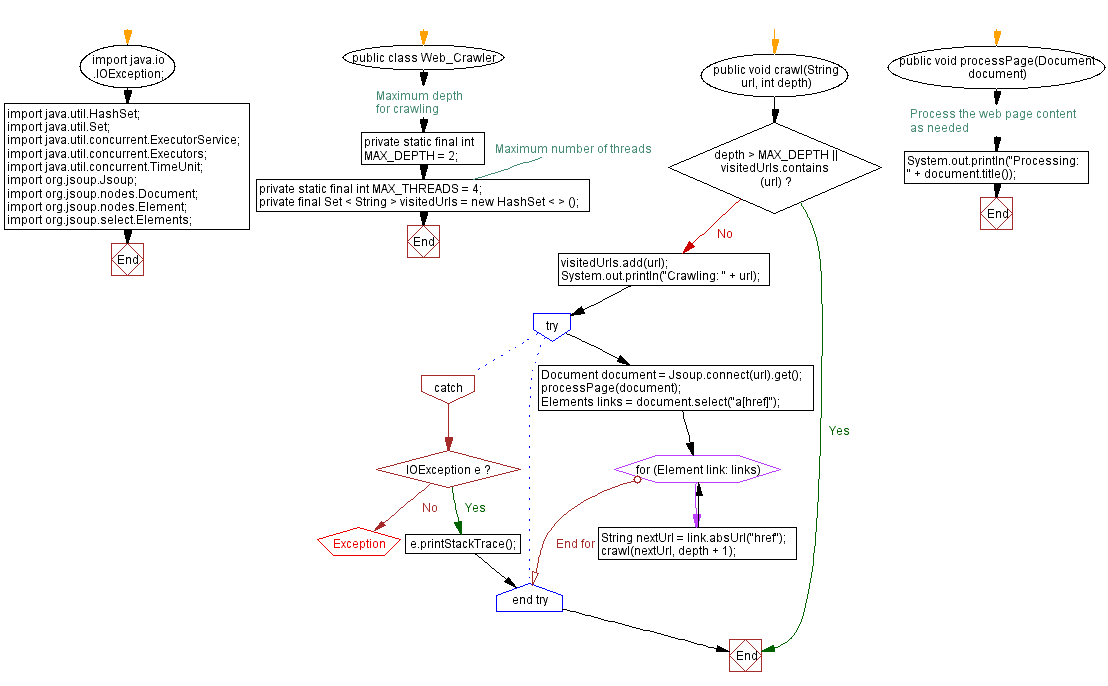
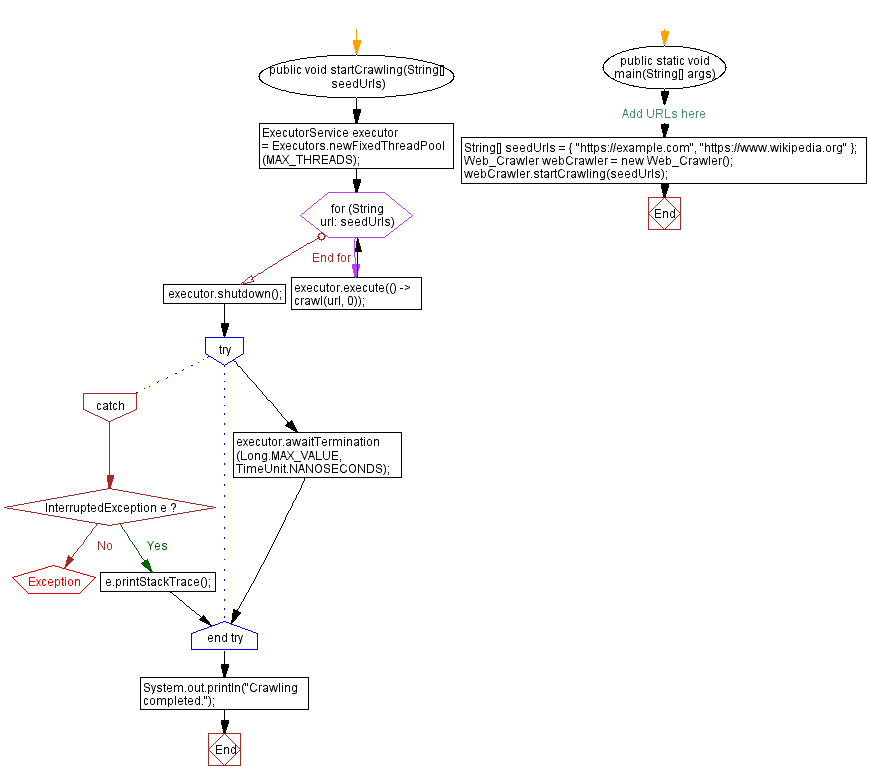
For more Practice: Solve these Related Problems:
- Write a Java program to implement a concurrent web crawler using threads that fetch URLs from a shared queue and process them simultaneously.
- Write a Java program to create a multi-threaded web crawler that uses synchronized blocks to prevent duplicate URL processing.
- Write a Java program to implement a web crawler using ExecutorService and Callable tasks to fetch website content with a timeout mechanism.
- Write a Java program to build a concurrent web crawler that aggregates data from multiple websites and stores results in a thread-safe collection.
Go to:
PREV : Sum prime numbers using multiple threads.
NEXT : Handle bank account with thread concurrency.
Java Code Editor:
Improve this sample solution and post your code through Disqus
What is the difficulty level of this exercise?
Test your Programming skills with w3resource's quiz.