C Exercises: Find the element(s) which occurs most frequently in a given sequence
Find the most frequently occurring number in a sequence
Write a C program that reads a sequence of integers and finds the element that occurs most frequently.
Sample Solution:
C Code:
#include <stdio.h>
#include<stdlib.h>
#include<math.h>
#include<string.h>
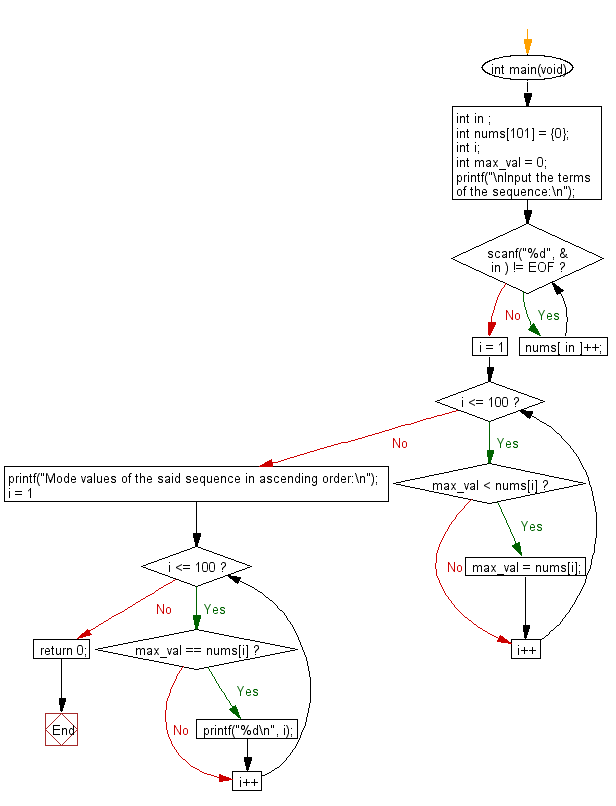
int main(void) {
int in;
int nums[101] = {0}; // Initialize an array to store frequency of each number (from 1 to 100)
int i;
int max_val = 0; // Variable to keep track of the maximum frequency
printf("\nInput the terms of the sequence:\n");
while (scanf("%d", &in) != EOF) // Keep reading numbers until end of input (EOF)
nums[in]++; // Increment the frequency count for the input number
// Find the maximum frequency
for (i = 1; i <= 100; i++) {
if (max_val < nums[i])
max_val = nums[i];
}
printf("Mode values of the said sequence in ascending order:\n");
// Print numbers that have the maximum frequency
for (i = 1; i <= 100; i++) {
if (max_val == nums[i])
printf("%d\n", i);
}
return 0; // End of the program
}
Sample Output:
Input the terms of the sequence: 5 2 4 6 8 10 ^Z Mode values of the said sequence in ascending order: 2 4 5 6 8 10
Flowchart:
For more Practice: Solve these Related Problems:
- Write a C program to read a sequence of integers and determine the mode using arrays for frequency counts.
- Write a C program to compute the most frequently occurring number by sorting the array first and then scanning.
- Write a C program to use a hash table (array-based) approach to track frequency and find the mode.
- Write a C program to determine and print the mode(s) of a sequence with proper handling of ties.
Go to:
PREV : Maximum sum of a contiguous subsequence in an array.
NEXT : Count digit combinations that sum to sss.
C programming Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
What is the difficulty level of this exercise?
Test your Programming skills with w3resource's quiz.